Research
Research Topics
Our current research is focussed on trustworthy experiential training of non-expert humans or agents (through reinforcement learning trainers) and assessing such trainers. The trustworthy experiential training and assessment of training requires:
- Reinforcement Learning based training that is constrained by a wide variety of preference and cost (expected, Var, CVaR, Worst case) based constraints on action and policy of the Reinforcement Learning trainer. These ensure safety, fairness and robustness constraints are handled.
- Solving the well known Unsupervised Environment Design for training not just agents, but also humans within a finite time horizon to enable experiential learning on part of trainees.
- Human behavioural models that are accurate and evolve as human trainee learning evolves. These are required to train RL trainers better.
- Adversarial attacks to poke holes in RL trainer and making RL trainers robust to such attacks.
Constrained Reinforcement Learning
Constrained Reinforcement Learning (CRL) is a variation of standard reinforcement learning (RL) designed to address the challenges of safety and costly mistakes in AI systems. Unlike standard RL, which relies on a trial-and-error method for learning optimal policies, CRL integrates cost functions or cost preferences into the environment. These cost functions restrict the AI agent from taking certain actions, thus guiding it towards safer and more reliable decision-making. CRL aims to balance task performance with safety requirements, making it crucial for creating advanced and safe AI systems.

Handling Long and Richly Constrained Tasks through Constrained Hierarchical Reinforcement Learning
Yuxiao Lu, Arunesh Sinha, Pradeep Varakantham
AAAI 2024
Imitate the Good and Avoid the Bad: An Incremental Approach to Safe Reinforcement Learning
Huy Hoang, Tien Mai, Pradeep Varakantham
AAAI 2024
Reward Penalties on Augmented States for Solving Richly Constrained RL Effectively
Hao Jiang, Tien Mai, Pradeep Varakantham, Huy Hoang
AAAI 2024
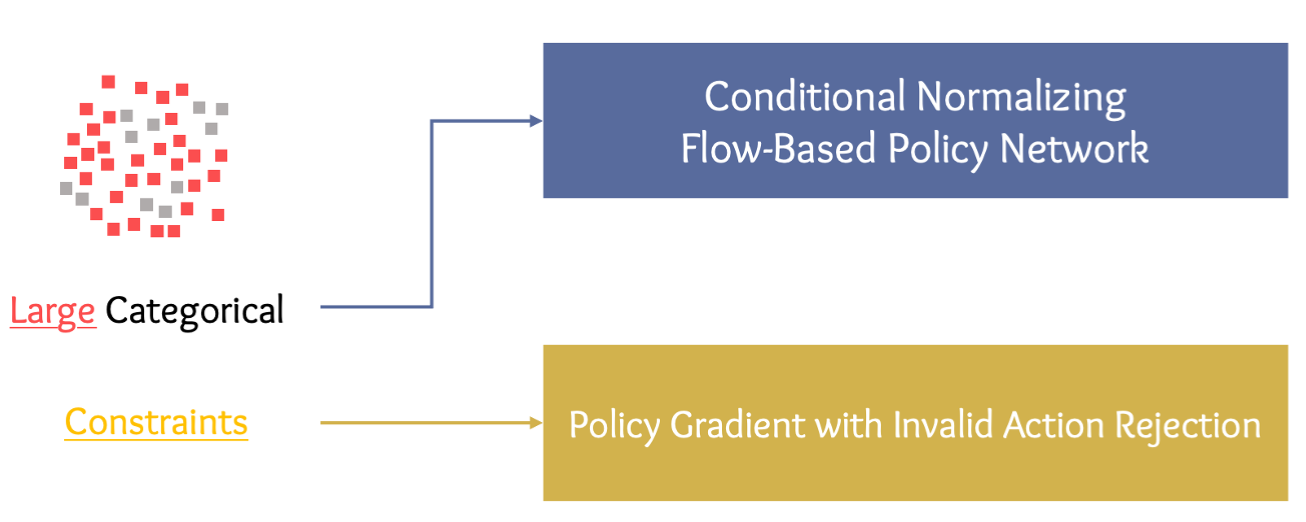
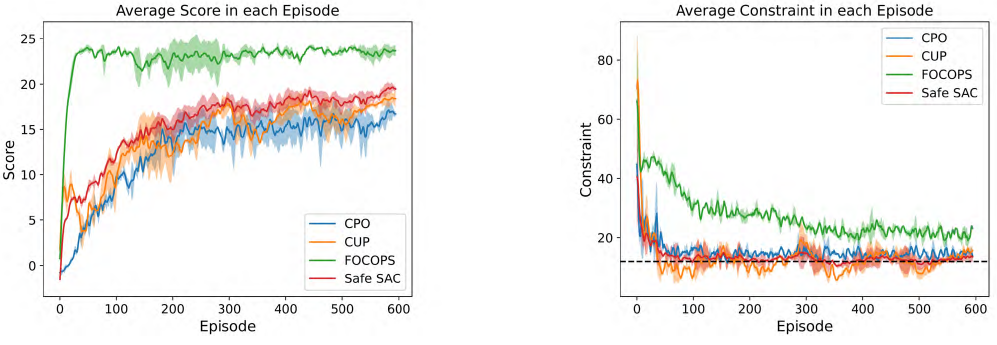
Generative Modelling of Stochastic Actions with Arbitrary Constraints in Reinforcement Learning
Changyu Chen, Ramesha Karunasena, Thanh Hong Nguyen, Arunesh Sinha, Pradeep Varakantham
NeurIPS 2023
Environment Generation
In order to train well-generalizing agents and non-expert humans, there is a need to generate scenarios which are at the "right" level of complexity to improve the agent/human ability. Our Environment Generation research focuses on crafting training environments automatically that adapt to the agent’s proficiency, fostering the acquisition of diverse skills. We prioritize critical environment properties, including learning potential, diversity, and marginal benefit, to ensure the creation of effective training scenarios. Beyond traditional RL simulations, our commitment extends to the real world, where we apply these environment generation algorithms to train non-expert humans.
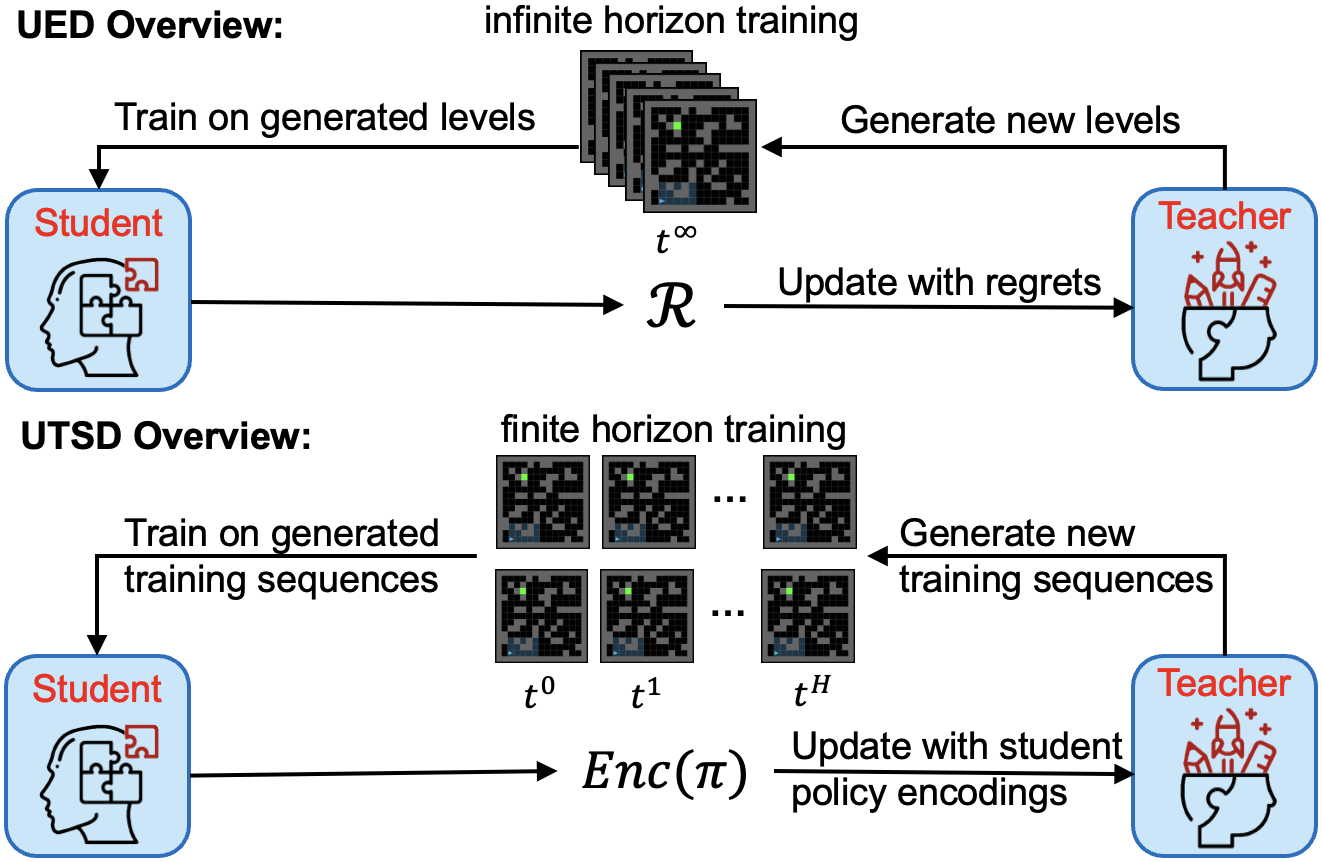
Unsupervised Training Sequence Design: Efficient and Generalizable Agent Training
Wenjun Li, Pradeep Varakantham
AAAI 2024
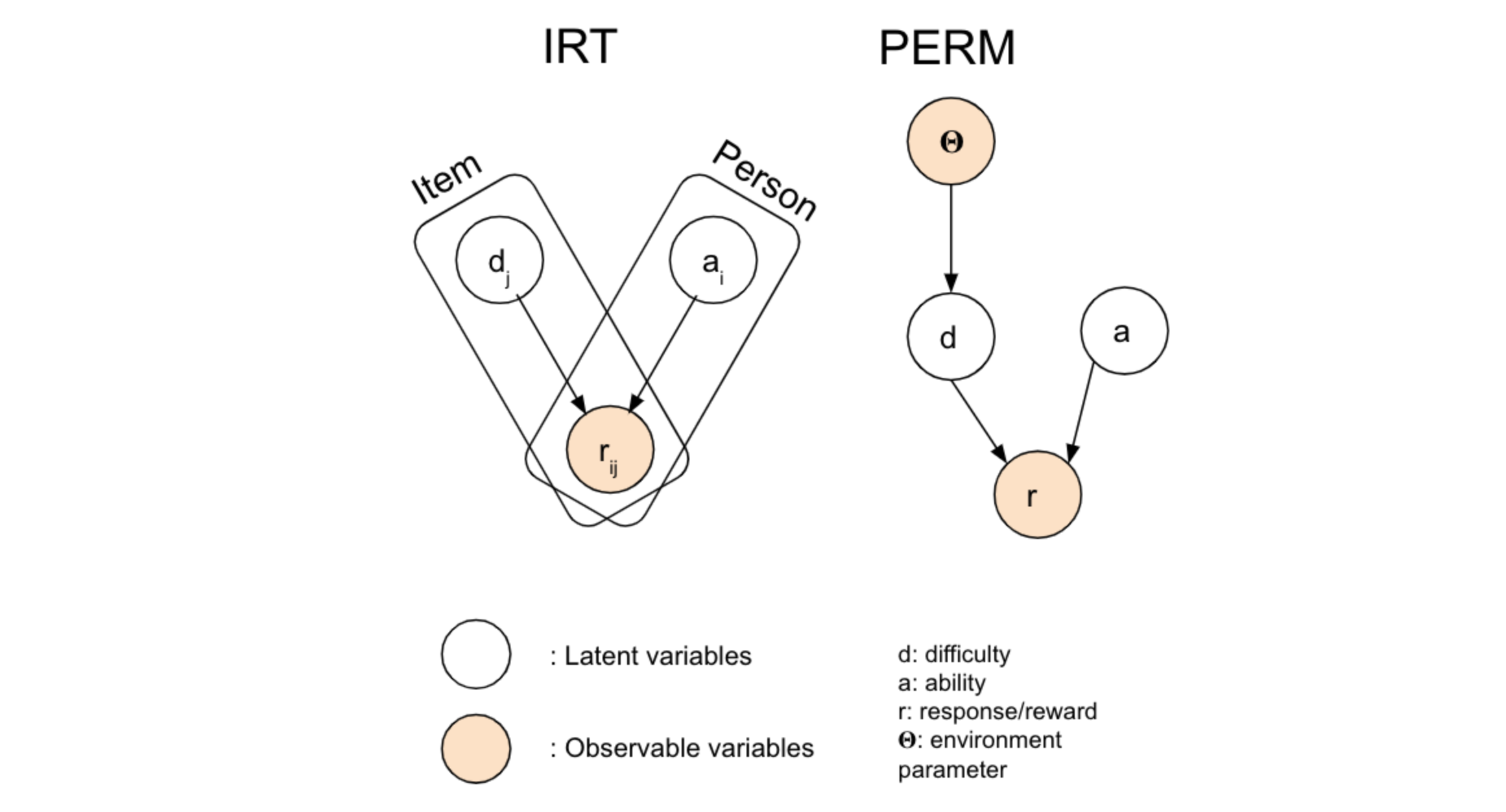
Transferable Curricula through Difficulty Conditioned Generators
Sidney Tio, Pradeep Varakantham
IJCAI 2023
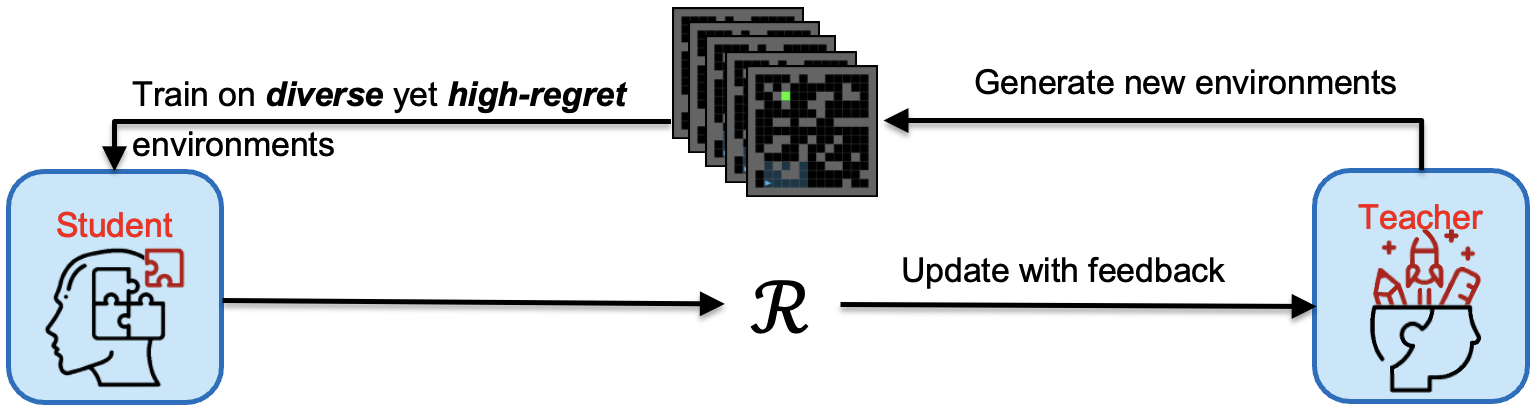
Generalization through Diversity: Improving Unsupervised Environment Design
Wenjun Li, Pradeep Varakantham, Dexun Li
IJCAI 2023
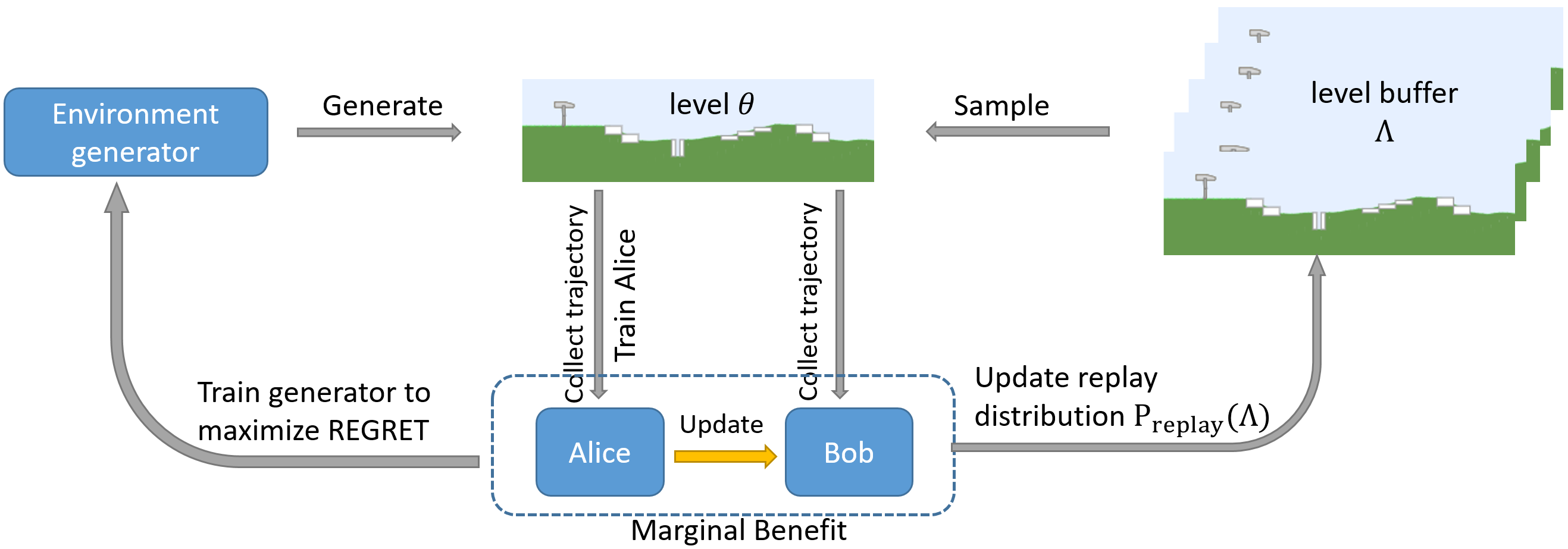
Marginal Benefit Induced Unsupervised Environment Design
Dexun Li, Wenjun Li, Pradeep Varakantham
Arxiv: 2302.02119
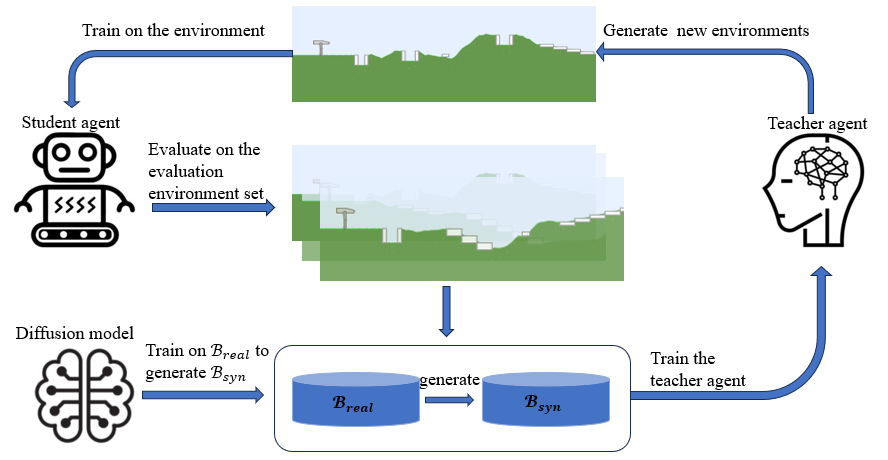
A Hierarchical Approach to Environment Design with Generative Trajectory Modeling
Dexun Li, Pradeep Varakantham
Arxiv: 2310.00301
Human Behavioral Modelling
Human behavior modeling involves constructing computational frameworks that emulate, predict, or analyze human actions, reactions, and decision-making processes. This field integrates various disciplines such as psychology, sociology, and computer science to develop algorithms and models that simulate human behavior in different scenarios. It encompasses the study of cognitive processes, emotions, social interactions, and decision-making patterns. Techniques like imitation learning are utilized to enable AI systems to learn from observed human behavior and replicate it in specific tasks or scenarios. Ultimately, the goal is to create AI systems capable of understanding, predicting, and interacting with humans more effectively and naturally.
Imitate the Good and Avoid the Bad: An Incremental Approach to Safe Reinforcement Learning
Huy Hoang, Tien Mai, Pradeep Varakantham
AAAI 2024
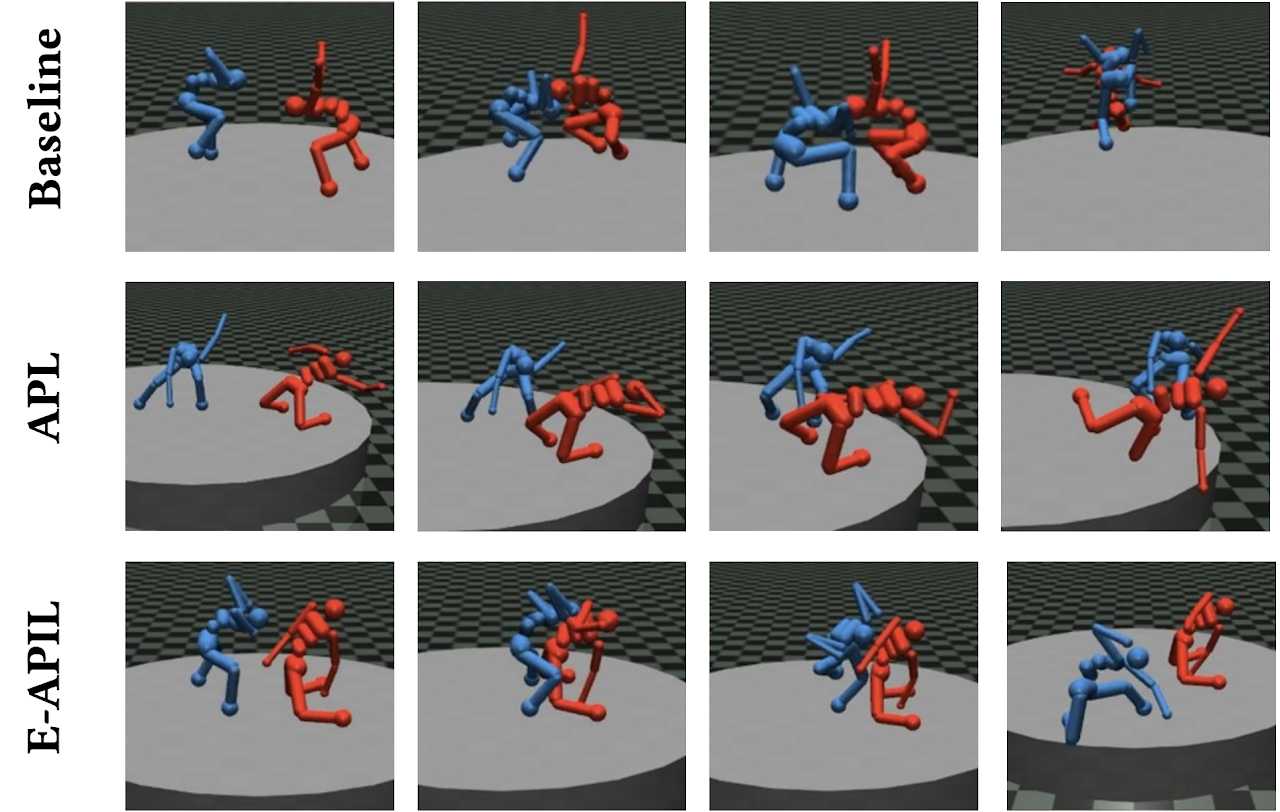
Imitating Opponent to Win: Adversarial Policy Imitation Learning in Two-player Competitive Games
The Viet Bui, Tien Mai, Thanh H. Nguyen
AAMAS 2023
Adversarial RL
Leading approaches for finding RL policies that are robust to an observation-perturbing adversary have focused on (a) regularization approaches that make expected value objectives robust by adding adversarial loss terms; or (b) employing "maximin" (i.e., maximizing the minimum value) notions of robustness. While regularization approaches are adept at reducing the probability of successful attacks, they remain vulnerable when an attack is successful. On the other hand, maximin objectives, while robust, can be too conservative to be useful. To this end, we focus on optimizing a well-studied robustness objective, namely regret. To ensure the solutions provided are not too conservative, we optimize an approximation of regret using three different methods.

Regret-based Defense in Adversarial Reinforcement Learning
Roman Belaire, Pradeep Varakantham, Thanh Nguyen, David Lo
AAMAS 2024